分类: 论文阅读
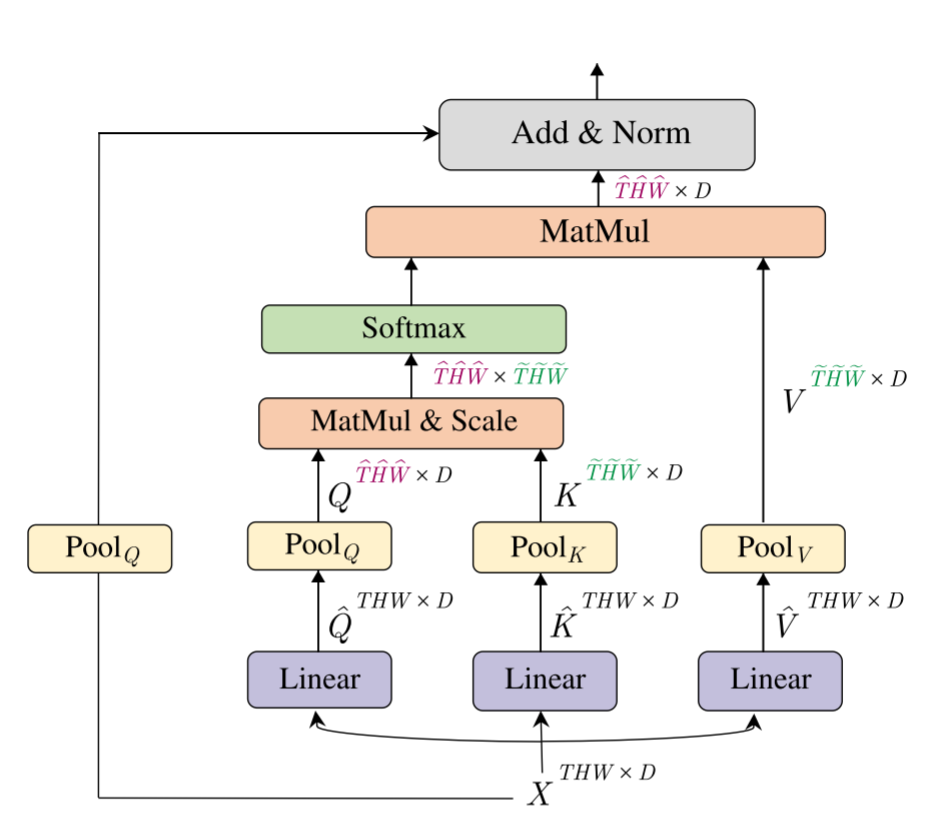
Multiscale Vision Transformer阅读笔记
前言
传统的Transformer在整个网络中会保持分辨率和通道数,本文提出了一种多尺度ViT模型,通过在网络中逐级地增加通道数,同时降低时空分辨率的手段来形成一……

SETR阅读笔记
概述
传统的语义分割任务使用全卷积神经网络FCN来实现。FCN采用Encoder-Decoder结构,其中Encoder负责学习输入图像的特征表示,Decoder负责对特征表示进行像素……

Vision Transformer阅读笔记
概述
自注意力结构的Transformer网络在NLP领域已经成为了事实上的霸主,但是在CV领域,应用仍然非常有限。目前的研究主要是集中在两个方面,一是将Self-Attent……