
前言
传统的Transformer在整个网络中会保持分辨率和通道数,本文提出了一种多尺度ViT模型,通过在网络中逐级地增加通道数,同时降低时空分辨率的手段来形成一种金字塔结构。
这样做的好处是,在不大量地增加计算量的前提下,浅层可以利用轻量的通道数去捕捉高分辨率的低级视觉信息,深层可以在低分辨率下捕捉更深层次的语义信息。
作者通过实验发现,MVit对视频的时间顺序敏感,当打乱视频帧的顺序后,会出现明显的性能下降,但是ViT不会,这说明ViT更多的依赖于视频的图像信息,没有很好地去学习视频的时序信息。
Multi-Head Pooling Attention(用来降低时空分辨率)
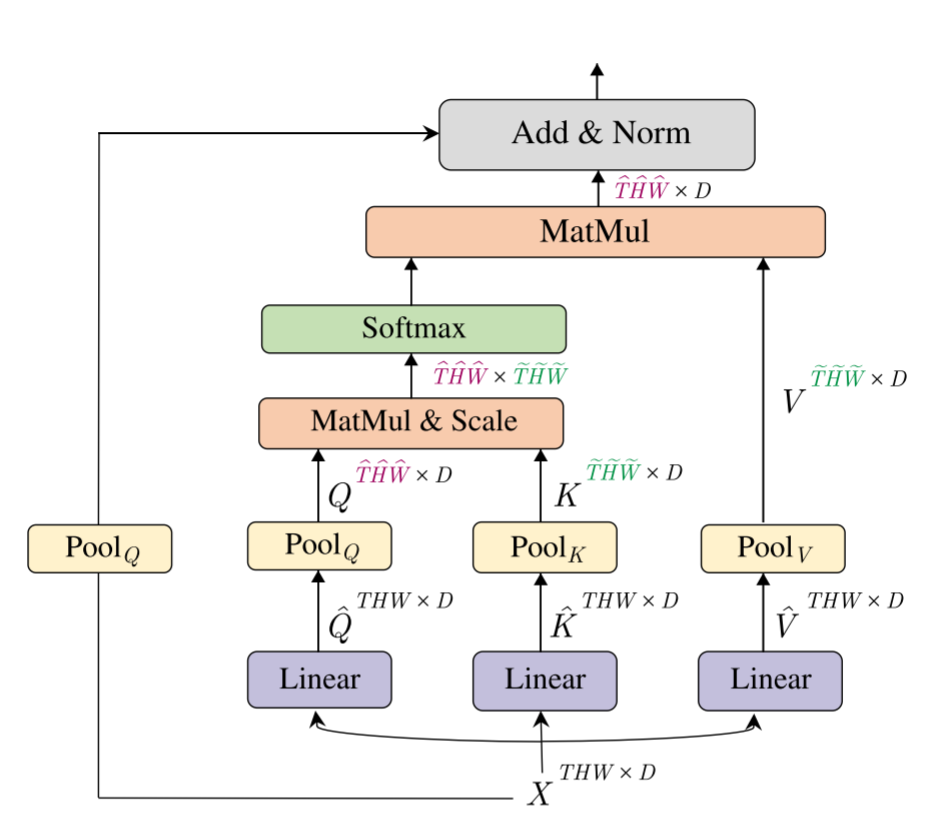
Channel Expansion (用来增加通道数)
在每个Transformer Block的最后一个MLP进行通道数的变化。由于涉及了残差连接,所以在Skip Connection上也要串联上一个Linear层用于变换维度。
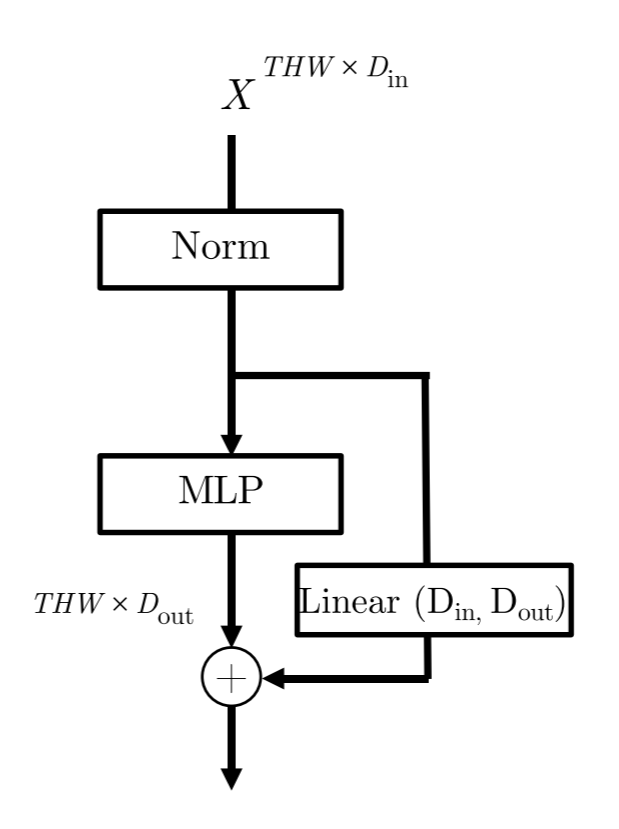
Base Model

每个Block进行时空分辨率减半,同时通道数乘二(和传统卷积类似)


