
概述
传统的语义分割任务使用全卷积神经网络FCN来实现。FCN采用Encoder-Decoder结构,其中Encoder负责学习输入图像的特征表示,Decoder负责对特征表示进行像素级分类。在这两个部分中,Encoder是比较重要的,但由于计算量的缘故,CNN必须通过堆叠的方式来逐级提升感受野,但这仍然无法很好的去捕捉到长距离的依赖信息。
为了解决感受野的问题,一些研究采用了空洞卷积和特征金字塔的手段,还有一些研究把注意力机制融入到FCN结构中去。当下还有一些研究尝试用Attention机制替代卷积操作,但这些研究还是没有改变FCN的本质——利用Encoder对输入图像进行下采样,然后利用Decoder进行上采样。
SETR提出了一种方法,这种方法既不使用堆叠的卷积结构,也不会在Encoder里逐级下采样。
模型结构

图像序列化
图像序列化的目的是把形如\mathbb{R}^{H \times W \times 3}的输入图像映射到\mathbb{R}^{L \times C},使之可以作为Transformer Encoder的输入。考虑到通常进行语义分割任务时会把输入图像提取成\mathbb{R}^{\frac{H}{16} \times \frac{W}{16} \times C},因此,本文把\mathbb{R}^{H \times W \times 3}的输入图像分割成\frac{H}{16} \times \frac{W}{16}的patch,然后压平成\mathbb{R}^{\frac{H \cdot W}{256} \times 3},再通过一个线性映射映射到C个通道,这样就满足了Transformer Encoder的输入特征维度。
同时,为了编码Patch间的位置信息,对序列中的每个向量叠加一个位置编码(就直接相加)。
Transformer
把上述形如\mathbb{R}^{L \times C}的序列输入Transformer编码器,就可以得到编码器的输出。考虑到Transformer编码器通常由多层堆叠形成,假设总层数为L_e,则各层输出的编码向量可以被表示为\{Z^1,Z^2,...,Z^{L_e}\}。
Decoder
Decoder的目标是把Encoder重构的特征Z重新映射回输入图像的形状并进行逐像素分类。
Naive 上采样
该方法首先将Encoder的最后一层输出Z^{L_e} \in \mathbb{R}^{\frac{H \cdot W}{256} \times C}的通道数映射成分类类别数(1*1 conv + sync batch norm(w/ReLU) + 1*1 conv),然后双线性上采样到原图大小,最后进行逐像素分类。
渐进式上采样
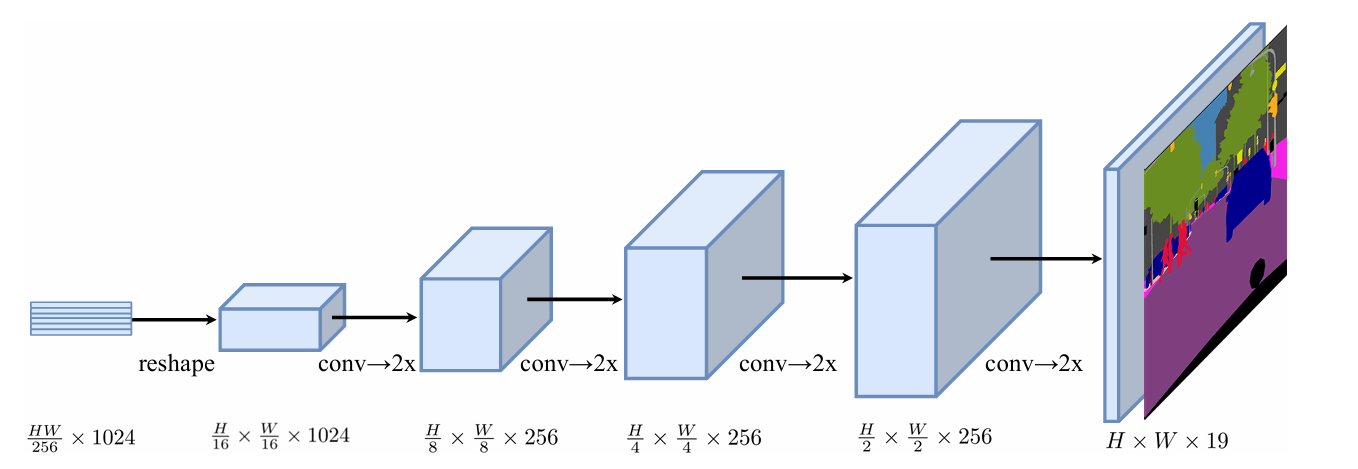
渐进式上采样轮流进行卷积和上采样操作,为了最大限度地避免不良反映,限制每次上采样2x,通过4步操作完成上采样。
多层特征融合的上采样
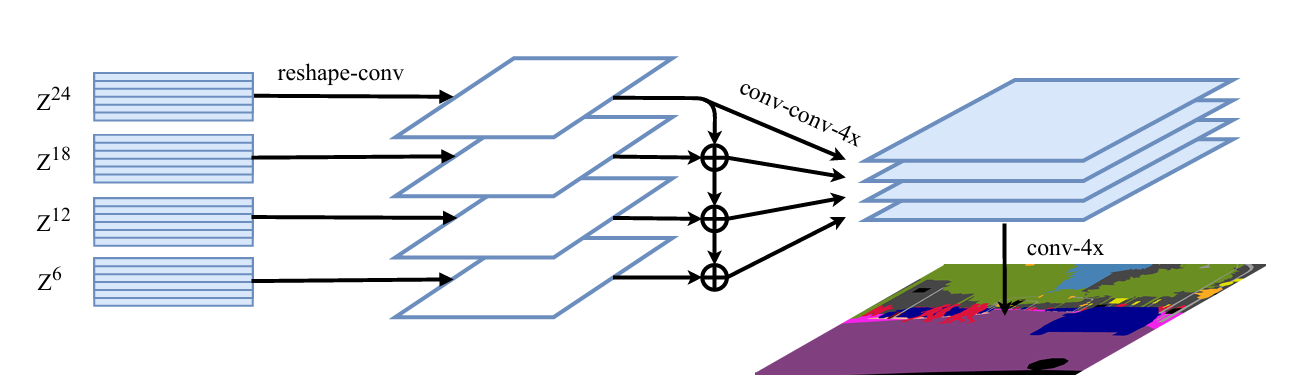
类似于特征金字塔,该方法等间隔地从所有Decoder层地输出中等间隔地选取M个输出,并将它们Reshape成\frac{H}{16} \times \frac{W}{16} \times C的形状。然后,使用一个三层的网络(1*1 conv + 3 * 3 conv + 3 * 3 conv)来对特征进行处理,其中第一和第三个conv会对通道数进行减半处理。接着使用双线性上采样到4x。为提升效果,第一个conv做完后,按自顶向下的顺序进行特征图相加来实现特征融合。
这个三层网络做完之后就会得到四个新特征图,每个特征图的形状是\frac{H}{4} \times \frac{W}{4} \times \frac{C}{4},对这四个特征图按channel维度进行concat,然后直接进行一个4x的双线性上采样,得到H \times W \times C的特征图,之后进行像素级分类即可。


