Vision Transformer阅读笔记
概述
自注意力结构的Transformer网络在NLP领域已经成为了事实上的霸主,但是在CV领域,应用仍然非常有限。目前的研究主要是集中在两个方面,一是将Self-Attention与CNN网络结合,二是直接用Self-Attention替换卷积操作。但这些结构没有很好的硬件加速。因此,在CV领域使用ResNet结构仍然是主流。
作者团队希望把标准的Transformer结构尽可能少更改地应用到CV领域。他们首先把图片分割成patch,然后把这些patch搞成一个线性的embedding序列输入到Transformer中(也就是说把图片的patch看作是NLP中的token),然后进行监督训练。
作者通过实验发现,ViT在大数据集(14M-300M)上表现很好,但是在中小数据集中,和CNN相比缺少归纳偏置(比如说平移不变性和局部性),因此效果欠佳。
归纳偏置(inductive bias)是指在机器学习算法中对模型进行偏好选择的先验假设或限制。这些偏好和限制可以通过算法设计、模型选择或数据预处理等方法来实现。
整体结构

对于输入的形如\mathbb{R}^{H \times W \times C}的图像,首先将他们分成N个patch,每个patch的大小是P \times P,然后对每个patch的特征图reshape成一个向量,整个图像就可以被reshape成形如\mathbb{R}^{N \times (P^2 \cdot C)}的矩阵,然后通过一个线性映射将矩阵映射为\mathbb{R}^{N \times D}(可以理解为一个句子有N个Token,每个Token用一个D维的向量来进行表示)。
接着,模仿BERT在输入特征前面添加一个可学习的cls token,这个cls token后续会充当输入图像的特征表示用来对输入图像进行分类。
然后进行位置编码,并输入到Transformer Encoder中,Encoder的输出取第0个(cls token)的特征重构输入到MLP Head进行分类。
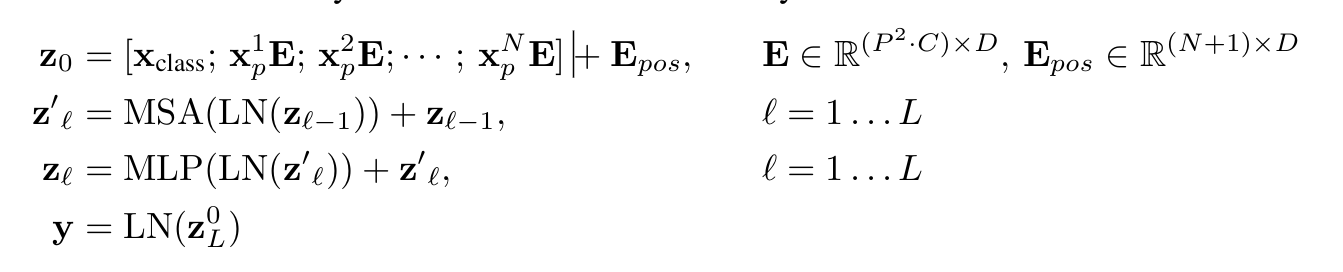
关于ViT归纳偏置的探讨
没有先验知识进行学习是不可能的。如果我们不对特征空间有先验假设,则所有算法的平均表现是一样的。对于,传统的CNN来说,整个网络结构中都广泛的存在二维邻域结构、局部性、平移不变性等先验假设。但是在ViT中,只有MLP层具有局部性和平移不变性,Self-Attention本身就是考虑全局的特征的。而且,在ViT中,二维邻域结构的使用非常少,只有在模型的开头通过将图像切成块,并在微调时调整不同分辨率图像的位置嵌入等少数场合使用到了。初始化时的位置嵌入不包含关于Patch的2D位置的信息,所有块之间的空间关系都必须从头开始学习。
与CNN进行融合
在把输入图片处理成patch的时候,除了直接对图片进行分割外,也可以用CNN先把输入图片处理成特征图,然后用一个1*1卷积把特征图处理成我们想要的维度。
ViT处理高分辨率图像的注意事项
- 在处理高分辨率的图像时,预训练使用的位置编码可能不在有意义,需要考虑对预训练的位置编码进行2D插值。